Multidimensional Expressions (MDX) lets you query multidimensional objects, such as cubes, and return multidimensional cell sets that contain the cube's data.
Microsoft SQL Server OLAP Services provides architecture for access to multidimensional data. This data is summarized, organized, and stored in multidimensional structures for rapid response to user queries. Through OLE DB for OLAP, a PivotTable Service provides client access to this multidimensional online analytical processing (OLAP) data. For expressing queries to this data, OLE DB for OLAP employs full-fledged, highly functional expression syntax: multidimensional expressions (MDX).
We are assuming the reader is familiar with multidimensional data warehousing and OLAP terms. Before talking about MDX and how it queries data, it is worthwhile to give a brief description of the structure of a cube.
Cubes:
Cubes are key elements in online analytic processing. They are subsets of data from the OLAP store, organized and summarized into multidimensional structures. These data summaries provide the mechanism that allows rapid and uniform response times to complex queries.
Cubes are the main objects in online analytic processing (OLAP), a technology that provides fast access to data in a data warehouse. A cube is a set of data that is usually constructed from a subset of a data warehouse and is organized and summarized into a multidimensional structure defined by a set of dimensions and measures.
The fundamental cube concepts to understand are dimensions and measures.
Dimensions provide the categorized descriptions by which the measures are separated for analysis such as Customers, geographical information and Products etc.
Measures identify the numerical values that are summarized for analysis, such as price, cost, or quantity sold.
A dimension can be created for use in an individual cube or in multiple cubes. A dimension created for an individual cube is called a private dimension, whereas a dimension that can be used by multiple cubes is called a shared dimension.
Pre-calculated summary data called aggregations provides the mechanism for rapid and uniform response times to queries. Aggregations are created for a cube before end users access it. The results of a query are retrieved from the aggregations, the cube's source data in the data warehouse, a copy of this data on the Analysis server, the client cache, or a combination of these sources. An Analysis server can support many different cubes, such as a cube for sales, a cube for inventory, a cube for customers, and so on.
Every cube has a schema, which is the set of joined tables in the data warehouse from which the cube draws its source data. The central table in the schema is the fact table, the source of the cube's measures. The other tables are dimension tables, the sources of the cube's dimensions.
Each cube dimension can contain a hierarchy of levels to specify the categorical breakdown available to users. For example, a Store dimension might include the following level hierarchy: Country, State, City, and Store Name. Each level in a dimension is of a finer grain than its parent. Similarly, the hierarchy of a time dimension might include levels for year, quarter, and month. Multiple hierarchies can exist for a single dimension.
For Example: The fiscal period hierarchy levels Fiscal Year, Fiscal Quarter, and Month. The calendar hierarchy levels Calendar Year, Calendar Quarter, and Month.
One final important item of note is the concept of a member. A member is nothing more than an item in a dimension or measure. A calculated member is a dimension member whose value is calculated at run time using a specified expression. Calculated members can also be defined as measures. Only the definitions for calculated members are stored; values are calculated in memory when needed to answer a query.
Getting Starters with MDX:
Let's start by outlining one of the simplest forms of an MDX expression, bearing in mind this is for an outline of an expression returning two cube dimensions:
SELECT (query) axis specification ON COLUMNS,
(query) axis specification ON ROWS
FROM cube_name
WHERE (slicer) axis specification
A SELECT clause that determines the query axes of an MDX SELECT statement. A FROM clause that determines which cube will be queried, An Optional WHERE clause that determines which members or tuples to use on the slicer axis to restrict the data returned.
Comparing the Syntax of the MDX SELECT Statement to SQL
The syntax format for the MDX SELECT statement is similar to that of SQL syntax. However, there are several fundamental differences:
1. MDX syntax distinguishes sets by surrounding tuples or members with braces (the { and } characters.)
2. MDX queries can have 0, 1, 2 or up to 128 query axes in the SELECT statement. Each axis behaves in exactly the same way, unlike SQL where there are significant differences between how the rows and the columns of a query behave.
3. As with an SQL query, the FROM clause names the source of the data for the MDX query. However, the MDX FROM clause is restricted to a single cube. Information from other cubes can be retrieved on a value-by-value basis by using the LookupCube function.
4. The WHERE clause describes the slicer axis in an MDX query. It acts as something like an invisible, extra axis in the query, slicing the values that appear in the cells in the result set; unlike the SQL WHERE clause it does not directly affect what appears on the rows axis of the query. The functionality of the SQL WHERE clause is available through other MDX functions such as the FILTER function.
SELECT Statement Example
The following example shows a basic MDX query that uses the SELECT statement. This query returns a result set that contains the 2002 and 2003 sales and tax amounts for the Southwest sales territories.
SELECT
{ [Measures].[Sales Amount],
[Measures].[Tax Amount] } ON COLUMNS,
{ [Date].[Fiscal].[Fiscal Year].&[2002],
[Date].[Fiscal].[Fiscal Year].&[2003] } ON ROWS
FROM [Adventure Works]
WHERE ( [Sales Territory].[Southwest] )
In this example, the query defines the following result set information:
1. The SELECT clause sets the query axes as the Sales Amount and Tax Amount members of the Measures dimension, and the 2002 and 2003 members of the Date dimension.
2. The FROM clause indicates that the data source is the Adventure Works cube.
3. The WHERE clause defines the slicer axis as the Southwest member of the Sales Territory dimension.
For more learning on MDX kindly wait for next article………….. Multidimensional Expressions (MDX): PART 2
Wednesday, June 30, 2010
Monday, June 28, 2010
Transact-SQL Improves Database Error-Handling
The robust Transact-SQL (T-SQL) syntax in SQL Server provides developers with an efficient way to handle errors within stored procedures. This article discusses the @@ERROR, SP_ADDMESSAGE, RAISERROR functions and Try…Catch block within SQL Server.
The @@Error Function
Upon the completion of any T-SQL statement, SQL Server sets the @@ERROR object. If the statement was successful, @@ERROR is set to 0, otherwise it is set to the designate error code.
All SQL Server error codes can be found within the master.dbo.sysmessages system table. One important thing to remember is that @@ERROR is cleared each time a statement is executed. It is a good practice to store the value within a local variable.
Anatomy of an Error
All errors raised by SQL Server return the following information.
• Number - Each error has a unique number assigned to it.
• Message - Contains information about the error. Many errors have substitution variables that can be placed within the text. We will cover this in the SP_ADDMESSAGE and RAISERROR sections.
• Transact-SQL Improves Database Error-Handling - Indicates how serious the error is. The values are between 1 and 25.
• State - As quoted from SQL Server books on line: "Some error codes can be raised at multiple points in the source code for SQL Server. For example, an 1105' error can be raised for several different conditions. Each place the error code is raised assigns a unique state code. A Microsoft support engineer can use the state code from an error to find the location in the source code where that error code is being raised, which may provide additional ideas on how to diagnose the problem."
• Procedure name - If the destruction occurred within a stored procedure, the name is returned.
• Line - The line number of the demon code.
There are two classes of error messages in SQL Server -- fatal and nonfatal. Remember that fatal errors will kill the client connection. Creating stored procedures that cause fatal errors is a good way to get rid of slacking programmers or consultants.
SP_ADDMESSAGE
Use the sp_addmessage feature to add your own customized messages. The following information is given about each parameter:
• @msgnum (smallint) - This is the message ID. All user-defined messages start with 50001. The combination of this parameter and language must be unique.
• @severity (smallint) - The severity level is between 1 and 25. Only the system administrator can add a message above the level of 18. Messages below the age of 18 are still considered to be "toddlers," and anyone can add them.
• @msgtext nvarchar(255) - This is the text of the error message. Variables can be used within the text. This functionality is similar to the printf feature within C.
• @lang - Since SQL Server can support different languages, you can store your error messages in multiple languages. This will help greatly when we start joint-developing with people from different planets. If left NULL, it will default to the default language of the current session.
• @with_log varchar(5) - This value can be TRUE or FALSE. If you set this parameter to "TRUE," then messages are written to the Windows and SQL Server application log.
• @replace varchar(7) - This allows you to replace an existing error message with a new message text and severity level. The default is NULL. This is a great way to tick the database administrator off!
RAISERROR
You can also use the RAISERROR command to create an error message. RAISERROR can send the error message information back to a client application.
The following information is given about the parameters.
• @msg_id - This is the message ID of your user-defined message. All adhoc error messages are given the message ID of 50000.
• @msg_str - The message can have up to 400 characters. If the message contains more than 400 characters, only the first 397 will be displayed and an ellipsis will be added to indicate that the message has been cut. You can also use formatting values within the message text. An example of this is given below.
• @argument - These are values to be used within the message text.
• @WITH - Acceptable values are LOG, NOWAIT, and SETERROR. The LOG option logs the error to the server and application log; NOWAIT sends the messages immediately back to the client application; and SETERROR sets the @@ERROR value to the @MSG_ID or 50000, regardless of the serverity level.
Sample Code
The User-defined Error Message
For the formatting, I will use %s for strings and %I for integers. This functionality is similar to the printf function in C. I know you still have those C notes from college somewhere!
USE master
EXEC sp_addmessage
50010, /*message id*/
16, /*severity level*/
'Error in stored procedure %s', /*message text*/
'us_english', /*language*/
'FALSE', /*log this error*/
NULL /*replace existing error*/
Using RAISERROR to Call the Error Message
I will use the pubs database for this demonstration.
Step 1. Create the following procedure.
CREATE PROCEDURE spDemo
AS BEGIN
SELECT TOP 10 * FROM AUTHORS
IF @@ROWCOUNT <>
Step 2. Execute the procedure.
Exec spDemo
You will then get the following error message.
"Server: Msg 50010, Level 12, State 1, Procedure spDemo, Line 5 Error in stored procedure Raise Error Demo"
Here is another example of using RAISERROR without a user-defined message.
RAISERROR ('An error occurred because we are overworked and underpaid!',10,1)
Real-World Use of @@ERROR and RAISERROR
Although common practice tells us that user validation goes on the front end, most database administrators (DBA) implement developer validation of the back -end. Experience has taught them that we cannot always be trusted to implement requirements correctly. Another valid reason would be that your database is being used by several different applications, and as an added precaution the DBA has decided to implement database-level validation.
Step 1. Create the following procedure in the pubs database.
CREATE PROCEDURE spDiscounts(@TYPE VARCHAR(40),
@STORE CHAR(4),@LOW SMALLINT, @HIGH SMALLINT, @DISCOUNT NUMERIC(9,2))
AS BEGIN
IF @DISCOUNT > 7
BEGIN
RAISERROR ('You entered %d, the discount can not be greater than 7.', 10, 1, @DISCOUNT)
END
ELSE
BEGIN
BEGIN TRANSACTION
INSERT INTO DISCOUNTS(DISCOUNTTYPE, STOR_ID, LOWQTY, HIGHQTY, DISCOUNT)
VALUES (@TYPE,@STORE,@LOW,@HIGH,@DISCOUNT)
IF @@ERROR <> 0
ROLLBACK TRANSACTION
ELSE
COMMIT TRANSACTION
END
END
Step 2. Execute the following procedure.
exec spDiscounts 'My Discount', NULL, 10, 100, 12
You will receive the following error message:
"You entered 12; the discount cannot be greater than 7."
Returning logical error messages like this to the client application will save hours of head scratching.
Try…….Catch Block
A TRY…CATCH construct catches all execution errors that have a severity higher than 10 that do not close the database connection.
A TRY block must be immediately followed by an associated CATCH block. Including any other statements between the END TRY and BEGIN CATCH statements generates a syntax error.
A TRY…CATCH construct cannot span multiple batches. A TRY…CATCH construct cannot span multiple blocks of Transact-SQL statements. For example, a TRY…CATCH construct cannot span two BEGIN…END blocks of Transact-SQL statements and cannot span an IF…ELSE construct.
If there are no errors in the code that is enclosed in a TRY block, when the last statement in the TRY block has finished running, control passes to the statement immediately after the associated END CATCH statement. If there is an error in the code that is enclosed in a TRY block, control passes to the first statement in the associated CATCH block. If the END CATCH statement is the last statement in a stored procedure or trigger, control is passed back to the statement that called the stored procedure or fired the trigger.
GOTO statements cannot be used to enter a TRY or CATCH block. GOTO statements can be used to jump to a label inside the same TRY or CATCH block or to leave a TRY or CATCH block.
The TRY…CATCH construct cannot be used in a user-defined function.
Retrieving Error Information
In the scope of a CATCH block, the following system functions can be used to obtain information about the error that caused the CATCH block to be executed:
ERROR_NUMBER() returns the number of the error.
ERROR_SEVERITY() returns the severity.
ERROR_STATE() returns the error state number.
ERROR_PROCEDURE() returns the name of the stored procedure or trigger where the error occurred.
ERROR_LINE() returns the line number inside the routine that caused the error.
ERROR_MESSAGE() returns the complete text of the error message. The text includes the values supplied for any substitutable parameters, such as lengths, object names, or times.
These functions return NULL if they are called outside the scope of the CATCH block. Error information can be retrieved by using these functions from anywhere within the scope of the CATCH block.
Errors Unaffected by a TRY…CATCH Construct
TRY…CATCH constructs do not trap the following conditions:
1. Warnings or informational messages that have a severity of 10 or lower.
2. Errors that have a severity of 20 or higher that stop the SQL Server Database Engine task processing for the session. If an error occurs that has severity of 20 or higher and the database connection is not disrupted, TRY…CATCH will handle the error.
3. Attentions, such as client-interrupt requests or broken client connections.
4. When the session is ended by a system administrator by using the KILL statement.
The following types of errors are not handled by a CATCH block when they occur at the same level of execution as the TRY…CATCH construct:
1. Compile errors, such as syntax errors, that prevent a batch from running.
2. Errors that occur during statement-level recompilation, such as object name resolution errors that occur after compilation because of deferred name resolution.
The @@Error Function
Upon the completion of any T-SQL statement, SQL Server sets the @@ERROR object. If the statement was successful, @@ERROR is set to 0, otherwise it is set to the designate error code.
All SQL Server error codes can be found within the master.dbo.sysmessages system table. One important thing to remember is that @@ERROR is cleared each time a statement is executed. It is a good practice to store the value within a local variable.
Anatomy of an Error
All errors raised by SQL Server return the following information.
• Number - Each error has a unique number assigned to it.
• Message - Contains information about the error. Many errors have substitution variables that can be placed within the text. We will cover this in the SP_ADDMESSAGE and RAISERROR sections.
• Transact-SQL Improves Database Error-Handling - Indicates how serious the error is. The values are between 1 and 25.
• State - As quoted from SQL Server books on line: "Some error codes can be raised at multiple points in the source code for SQL Server. For example, an 1105' error can be raised for several different conditions. Each place the error code is raised assigns a unique state code. A Microsoft support engineer can use the state code from an error to find the location in the source code where that error code is being raised, which may provide additional ideas on how to diagnose the problem."
• Procedure name - If the destruction occurred within a stored procedure, the name is returned.
• Line - The line number of the demon code.
There are two classes of error messages in SQL Server -- fatal and nonfatal. Remember that fatal errors will kill the client connection. Creating stored procedures that cause fatal errors is a good way to get rid of slacking programmers or consultants.
SP_ADDMESSAGE
Use the sp_addmessage feature to add your own customized messages. The following information is given about each parameter:
• @msgnum (smallint) - This is the message ID. All user-defined messages start with 50001. The combination of this parameter and language must be unique.
• @severity (smallint) - The severity level is between 1 and 25. Only the system administrator can add a message above the level of 18. Messages below the age of 18 are still considered to be "toddlers," and anyone can add them.
• @msgtext nvarchar(255) - This is the text of the error message. Variables can be used within the text. This functionality is similar to the printf feature within C.
• @lang - Since SQL Server can support different languages, you can store your error messages in multiple languages. This will help greatly when we start joint-developing with people from different planets. If left NULL, it will default to the default language of the current session.
• @with_log varchar(5) - This value can be TRUE or FALSE. If you set this parameter to "TRUE," then messages are written to the Windows and SQL Server application log.
• @replace varchar(7) - This allows you to replace an existing error message with a new message text and severity level. The default is NULL. This is a great way to tick the database administrator off!
RAISERROR
You can also use the RAISERROR command to create an error message. RAISERROR can send the error message information back to a client application.
The following information is given about the parameters.
• @msg_id - This is the message ID of your user-defined message. All adhoc error messages are given the message ID of 50000.
• @msg_str - The message can have up to 400 characters. If the message contains more than 400 characters, only the first 397 will be displayed and an ellipsis will be added to indicate that the message has been cut. You can also use formatting values within the message text. An example of this is given below.
• @argument - These are values to be used within the message text.
• @WITH - Acceptable values are LOG, NOWAIT, and SETERROR. The LOG option logs the error to the server and application log; NOWAIT sends the messages immediately back to the client application; and SETERROR sets the @@ERROR value to the @MSG_ID or 50000, regardless of the serverity level.
Sample Code
The User-defined Error Message
For the formatting, I will use %s for strings and %I for integers. This functionality is similar to the printf function in C. I know you still have those C notes from college somewhere!
USE master
EXEC sp_addmessage
50010, /*message id*/
16, /*severity level*/
'Error in stored procedure %s', /*message text*/
'us_english', /*language*/
'FALSE', /*log this error*/
NULL /*replace existing error*/
Using RAISERROR to Call the Error Message
I will use the pubs database for this demonstration.
Step 1. Create the following procedure.
CREATE PROCEDURE spDemo
AS BEGIN
SELECT TOP 10 * FROM AUTHORS
IF @@ROWCOUNT <>
Step 2. Execute the procedure.
Exec spDemo
You will then get the following error message.
"Server: Msg 50010, Level 12, State 1, Procedure spDemo, Line 5 Error in stored procedure Raise Error Demo"
Here is another example of using RAISERROR without a user-defined message.
RAISERROR ('An error occurred because we are overworked and underpaid!',10,1)
Real-World Use of @@ERROR and RAISERROR
Although common practice tells us that user validation goes on the front end, most database administrators (DBA) implement developer validation of the back -end. Experience has taught them that we cannot always be trusted to implement requirements correctly. Another valid reason would be that your database is being used by several different applications, and as an added precaution the DBA has decided to implement database-level validation.
Step 1. Create the following procedure in the pubs database.
CREATE PROCEDURE spDiscounts(@TYPE VARCHAR(40),
@STORE CHAR(4),@LOW SMALLINT, @HIGH SMALLINT, @DISCOUNT NUMERIC(9,2))
AS BEGIN
IF @DISCOUNT > 7
BEGIN
RAISERROR ('You entered %d, the discount can not be greater than 7.', 10, 1, @DISCOUNT)
END
ELSE
BEGIN
BEGIN TRANSACTION
INSERT INTO DISCOUNTS(DISCOUNTTYPE, STOR_ID, LOWQTY, HIGHQTY, DISCOUNT)
VALUES (@TYPE,@STORE,@LOW,@HIGH,@DISCOUNT)
IF @@ERROR <> 0
ROLLBACK TRANSACTION
ELSE
COMMIT TRANSACTION
END
END
Step 2. Execute the following procedure.
exec spDiscounts 'My Discount', NULL, 10, 100, 12
You will receive the following error message:
"You entered 12; the discount cannot be greater than 7."
Returning logical error messages like this to the client application will save hours of head scratching.
Try…….Catch Block
A TRY…CATCH construct catches all execution errors that have a severity higher than 10 that do not close the database connection.
A TRY block must be immediately followed by an associated CATCH block. Including any other statements between the END TRY and BEGIN CATCH statements generates a syntax error.
A TRY…CATCH construct cannot span multiple batches. A TRY…CATCH construct cannot span multiple blocks of Transact-SQL statements. For example, a TRY…CATCH construct cannot span two BEGIN…END blocks of Transact-SQL statements and cannot span an IF…ELSE construct.
If there are no errors in the code that is enclosed in a TRY block, when the last statement in the TRY block has finished running, control passes to the statement immediately after the associated END CATCH statement. If there is an error in the code that is enclosed in a TRY block, control passes to the first statement in the associated CATCH block. If the END CATCH statement is the last statement in a stored procedure or trigger, control is passed back to the statement that called the stored procedure or fired the trigger.
GOTO statements cannot be used to enter a TRY or CATCH block. GOTO statements can be used to jump to a label inside the same TRY or CATCH block or to leave a TRY or CATCH block.
The TRY…CATCH construct cannot be used in a user-defined function.
Retrieving Error Information
In the scope of a CATCH block, the following system functions can be used to obtain information about the error that caused the CATCH block to be executed:
ERROR_NUMBER() returns the number of the error.
ERROR_SEVERITY() returns the severity.
ERROR_STATE() returns the error state number.
ERROR_PROCEDURE() returns the name of the stored procedure or trigger where the error occurred.
ERROR_LINE() returns the line number inside the routine that caused the error.
ERROR_MESSAGE() returns the complete text of the error message. The text includes the values supplied for any substitutable parameters, such as lengths, object names, or times.
These functions return NULL if they are called outside the scope of the CATCH block. Error information can be retrieved by using these functions from anywhere within the scope of the CATCH block.
Errors Unaffected by a TRY…CATCH Construct
TRY…CATCH constructs do not trap the following conditions:
1. Warnings or informational messages that have a severity of 10 or lower.
2. Errors that have a severity of 20 or higher that stop the SQL Server Database Engine task processing for the session. If an error occurs that has severity of 20 or higher and the database connection is not disrupted, TRY…CATCH will handle the error.
3. Attentions, such as client-interrupt requests or broken client connections.
4. When the session is ended by a system administrator by using the KILL statement.
The following types of errors are not handled by a CATCH block when they occur at the same level of execution as the TRY…CATCH construct:
1. Compile errors, such as syntax errors, that prevent a batch from running.
2. Errors that occur during statement-level recompilation, such as object name resolution errors that occur after compilation because of deferred name resolution.
Wednesday, June 23, 2010
Metadata for Data Warehousing and Business Intelligence
Metadata is one of the important keys to the success of the data warehousing and business intelligence effort. Metadata management answers these questions:
What is Metadata?
How can Metadata be Managed?
Extracting Metadata from Legacy Systems
What is Metadata?
Metadata is your control panel to the data warehouse. It is data that describes the data warehousing and business intelligence system:
1. Reports
2. Cubes
3. Tables (Records, Segments, Entities, etc.)
4. Columns (Fields, Attributes, Data Elements, etc.)
5. Keys
6. Indexes
Metadata is often used to control the handling of data and describes:
1. Rules
2. Transformations
3. Aggregations
4. Mappings
The power of metadata is that enables data warehousing personnel to develop and control the system without writing code in languages such as: Java, C# or Visual Basic. This saves time and money both in the initial set up and on going management.
Data Warehouse Metadata
Data warehousing has specific metadata requirements. Metadata that describes tables typically includes:
1. Physical Name
2. Logical Name
3. Type: Fact, Dimension, Bridge
4. Role: Legacy, OLTP, Stage,
5. DBMS: DB2, Informix, MS SQL Server, Oracle, Sybase
6. Location
7. Definition
8. Notes
Metadata describes columns within tables:
1. Physical Name
2. Logical Name
3. Order in Table
4. Datatype
5. Length
6. Decimal Positions
7. Nullable/Required
8. Default Value
9. Edit Rules
10.Definition
11.Notes
How can Data Warehousing Metadata be Managed?
Data warehousing and business intelligence metadata is best managed through a combination of people, process and tools.
The people side requires that people be trained in the importance and use of metadata. They need to understand how and when to use tools as well as the benefits to be gained through metadata.
The process side incorporates metadata management into the data warehousing and business intelligence life cycle. As the life cycle progresses metadata is entered into the appropriate tool and stored in a metadata repository for further use.
Metadata can be managed through individual tools:
Metadata manager / repository
Metadata extract tools
Data modeling
ETL
BI Reporting
Metadata Manager / Repository
Metadata can be managed through a shared repository that combines information from multiple sources.
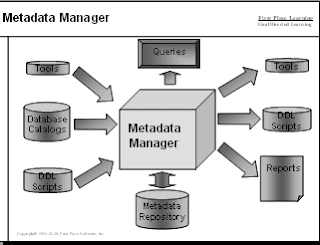
The metadata manager can be purchased as a software package or built as "home grown" system. Many organizations start with a spreadsheet containing data definitions and then grow to a more sophisticated approach.
Extracting Metadata from Input Sources
Metadata can be obtained through a manual process of keying in metadata or through automated processes. Scanners can extract metadata from text such as SQL DDL or COBOL programs. Other tools can directly access metadata through SQL catalogs and other metadata sources.
Picking the appropriate metadata extract tools is a key part of metadata management.
Many data modeling tools include a metadata extract capability - otherwise known as "reverse engineering". Through this tool, database information about tables and columns can be extracted. The information can then be exported from the data modeling tool to the metadata manager.
What is Metadata?
How can Metadata be Managed?
Extracting Metadata from Legacy Systems
What is Metadata?
Metadata is your control panel to the data warehouse. It is data that describes the data warehousing and business intelligence system:
1. Reports
2. Cubes
3. Tables (Records, Segments, Entities, etc.)
4. Columns (Fields, Attributes, Data Elements, etc.)
5. Keys
6. Indexes
Metadata is often used to control the handling of data and describes:
1. Rules
2. Transformations
3. Aggregations
4. Mappings
The power of metadata is that enables data warehousing personnel to develop and control the system without writing code in languages such as: Java, C# or Visual Basic. This saves time and money both in the initial set up and on going management.
Data Warehouse Metadata
Data warehousing has specific metadata requirements. Metadata that describes tables typically includes:
1. Physical Name
2. Logical Name
3. Type: Fact, Dimension, Bridge
4. Role: Legacy, OLTP, Stage,
5. DBMS: DB2, Informix, MS SQL Server, Oracle, Sybase
6. Location
7. Definition
8. Notes
Metadata describes columns within tables:
1. Physical Name
2. Logical Name
3. Order in Table
4. Datatype
5. Length
6. Decimal Positions
7. Nullable/Required
8. Default Value
9. Edit Rules
10.Definition
11.Notes
How can Data Warehousing Metadata be Managed?
Data warehousing and business intelligence metadata is best managed through a combination of people, process and tools.
The people side requires that people be trained in the importance and use of metadata. They need to understand how and when to use tools as well as the benefits to be gained through metadata.
The process side incorporates metadata management into the data warehousing and business intelligence life cycle. As the life cycle progresses metadata is entered into the appropriate tool and stored in a metadata repository for further use.
Metadata can be managed through individual tools:
Metadata manager / repository
Metadata extract tools
Data modeling
ETL
BI Reporting
Metadata Manager / Repository
Metadata can be managed through a shared repository that combines information from multiple sources.

The metadata manager can be purchased as a software package or built as "home grown" system. Many organizations start with a spreadsheet containing data definitions and then grow to a more sophisticated approach.
Extracting Metadata from Input Sources
Metadata can be obtained through a manual process of keying in metadata or through automated processes. Scanners can extract metadata from text such as SQL DDL or COBOL programs. Other tools can directly access metadata through SQL catalogs and other metadata sources.
Picking the appropriate metadata extract tools is a key part of metadata management.
Many data modeling tools include a metadata extract capability - otherwise known as "reverse engineering". Through this tool, database information about tables and columns can be extracted. The information can then be exported from the data modeling tool to the metadata manager.
Subscribe to:
Posts (Atom)


